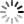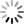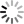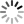

A turno, bendati, bisogna scoprire gli occhi e leggere immediatamente e correttamente la parola sul cartoncino: se tentennate dovete bere, se sbagliate a leggere bevete. Il gioco finisce dopo che avete letto le quattro parole: “rosso” in rosso e verde, “verde” in rosso e verde. Divertimento assicurato.
Cosa succede? Nei primi 20 millisecondi la retina ha visto il cartoncino, nei successivi 20 la parte posteriore del cervello ha riconosciuto i contorni delle parole, nei successivi 100 vicino alla spina dorsale avete letto la parola, in altri 200 avete riconosciuto il colore ed associato alla parola nella corteccia prefrontale, e negli ultimi 140 avete aperto bocca e dato la risposta, dalla parte alta del cervello. In 480 millisecondi avete visto, capito, scelto accendendo un enormità di neuroni e sinapsi dagli occhi attraverso il cervello. Sembrate un albero di natale a vedervi da una risonanza magnetica.
Come in una casa, l’input partito dagli occhi è salito attraverso vari piani di neuroni fino a farvi dare la risposta, e ad un paio di piani avete attinto alla memoria che vi fa ricordare cosa vuol dire verde, rosso e rispettivi colori. Il bello del gioco è che il nostro cervello va alla grande nel leggere rosso se il cartoncino è rosso, o verde su verde, ma non quando colore e parola si mischiano. E se cominciate a bere, il gioco diventa difficile  .
.
Per chi volesse entrare nei dettagli, raccomando di leggere dell’esperimento di Stroop e magari fare il gioco su internet qui e di approfondire il modello CDM di Cohen, Dunbar e McClellan qui.
Ecco in pratica cos’è e come funziona un network neuronale: ricostruire il passaggio dei dati dalle fonti di input attraverso tutti i livelli dove questi vengono processati, messi in memoria e paragonati con quelli già disponibili, prima di farci aprir bocca, sbagliare e bere un bicchiere di rosso. Dalla comprensione di questi meccanismi neurologici, possiamo progettare equivalenti circuiti elettronici che consentono al robot di riconoscere un qualcosa e di conseguenza fare una determinata azione. I tempi di reazione sono leggermente inferiori ed i neuroni del robot sono un quarto dei nostri, ma il meccanismo è lo stesso.
Un esempio è il robottino bostoniano iRoomba, che da 30 anni pulisce per terra. I primi modelli usavano il tatto per costruirsi una mappa di casa ed assicurarsi di passare dappertutto, oggi siamo arrivati a riconoscimento visivo e vocale, per cui gli potete dire di pulire sotto il tavolo dopo pranzo e lui esegue. Pensate sia facile? Muri e mobili sono fissi, ma sedie ed altri oggetti sono mobili, poi ci sono persone ed animali domestici che si muovono. Serve appunto combinare più input: tattili, visivi e vocali per aumentare l’efficienza e la velocità della pulizia. $200 dollari sono tanti o pochi per un robottino che spazza in casa a comando? A lui i bicchieri di rosso non interessano, e voi potete giocare coi cartoncini colorati mentre lui pulisce in casa.
